
🤦 Progress like DeepSeek are what the pessimists always miss
AI development was heading for a wall, said the pessimists. Then DeepSeek appeared and shattered their argument.
Share this story!
AI development is slowing down and approaching a wall, more and more people have claimed recently. Their argument is that AI models have improved by being trained on increasingly large amounts of data, but that there isn't much new data left. They've already devoured most of what's available on the internet, so they won't be able to improve further.
But lo and behold, DeepSeek appeared!
DeepSeek is a new Chinese AI service. Their model, R1, performed at the same level as models from OpenAI, Google, and Meta but was significantly cheaper to train. The reason? They made it train itself by giving it incentives to learn. When you train a dog to do tricks, you reward it with a treat when it does well. Similarly, the AI earns points when it reaches the correct answer and also when it reasons well to get there. This approach is called reinforcement learning.
Aha!
DeepSeek started by developing a base model in a similar way to OpenAI and the others—using reinforcement learning combined with human feedback to guide it toward the right answers and resolve tricky situations. But to teach the model how to reason—meaning to reach an answer step by step—they removed the humans. The base model was given a set of questions to answer and had to figure out how to do so on its own.
The progress was slow at first, but eventually, the penny dropped. Aha! And that is exactly what the model itself calls it—an aha moment. While solving an equation, it suddenly stops and says to itself: "Wait, wait. Wait."
It realized it needed to backtrack and reassess its solution by reviewing its previous steps. The model had taught itself to question its own reasoning and make adjustments.
For the developers, this was also an aha moment. "Rather than explicitly teaching the model how to solve a problem, we simply give it the right incentives, and it develops advanced problem-solving strategies on its own," they wrote.
Pocket change
This model was called R1 Zero because no humans were involved in its training. However, it wasn’t practical for human users because its reasoning was often difficult to understand. So, based on R1 Zero, they developed the R1 model, which built upon Zero but was supplemented with foundational data to make it more comprehensible for us flesh intelligences.
Training this model, R1, was highly efficient, costing less than $6 million. Pocket change in this context. It required fewer and less powerful chips for training, which caused Nvidia’s stock price to plummet. Nvidia, the leading manufacturer of AI chips, lost $600 billion in market value in a single day. Ouch.
That reaction was quite exaggerated. While training R1 was relatively cheap, it didn’t account for the costs of developing the base model and R1 Zero, nor the thousands of developer hours that preceded the training. Even so, DeepSeek was a clear step forward in efficiency and creativity.
Naive pessimists
This is exactly what pessimists keep missing. To be charitable, one could say they live in the present. Their standard argument is that if we want to build X, it will require a massive amount of Y—and Y is either unavailable, incredibly expensive, or outright impossible.
Let’s take something completely different as an example, cobalt in batteries. Here’s how pessimists argue:
- Cobalt is often mined under poor conditions.
- If we want many electric cars, we’ll need enormous amounts of cobalt.
- That means massive suffering.
- Therefore, we cannot/should not scale up electric vehicle production.
But that’s not how things work. The reality is shown in this graph, which displays the demand for cobalt from 2019 to 2022.
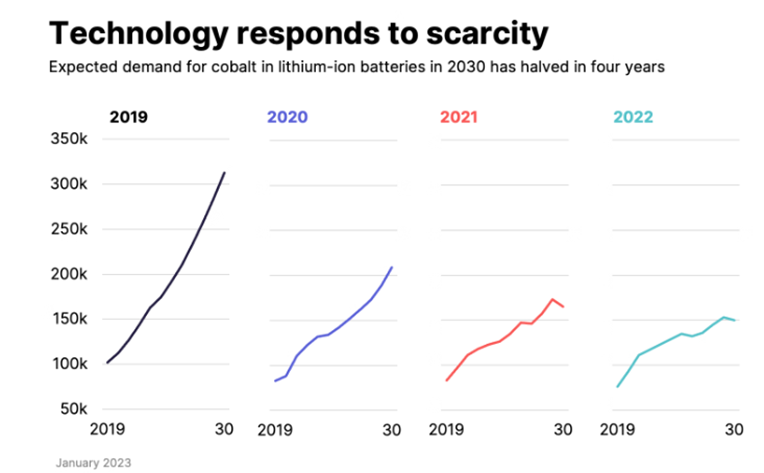
When we encounter shortages or problems, we develop alternatives. Again and again, pessimists fail to see this! And yet, they call optimists naive…
Chip shortages led to…
The U.S. has imposed export restrictions on China for the best AI chips. As a result, China doesn’t have enough high-quality chips to train models at the same level as American competitors. This forced them to think differently—and voilà, DeepSeek was born.
Compare this to Elon Musk’s xAI. Grok 3 was recently released and performs on par with the best models. They achieved this with sheer brute force, building a data center with 200,000 of Nvidia’s most powerful GPUs (likely setting a world record for how quickly such a massive data center was built).
Pessimists may be right that low-hanging data is running out, meaning we can no longer improve models easily by adding more data. But there is still plenty of data that can be made available. This was something we examined in the Swedish AI Commission. For example, Sweden’s National Library holds vast amounts of information that isn’t yet digitized and accessible. When it becomes profitable and important to make that data available, it will happen.
Additionally, we will discover new ways to train AI models. DeepSeek has taken the first step in that direction, but many others will follow.
Nobody wants to fly that short
At a talk by Troed Troedson, he said something insightful:
What did the pessimist say in 1903 when they heard that humans had flown a airplane for the first time, covering a distance of 120 feet?
"Nobody wants to fly that short."
Mathias Sundin
Angry Optimist
By becoming a premium supporter, you help in the creation and sharing of fact-based optimistic news all over the world.


