
💡 Musings of the Angry Optimist: AI development has entered phase two
AI development has now entered Phase Two, where we create new things based on what we learned in Phase One. It may seem obvious, yet surprisingly many people focus only on today’s shortcomings and completely misjudge the future.
Share this story!
My thoughts, tips, and other tidbits that I believe are suited for a fact-based optimist. This newsletter is for you who are a Premium Supporter at Warp News. Feel free to share it with friends and acquaintances.
🤖 Phase two
After the release of ChatGPT in November 2022, AI development over the following two years mainly consisted of using more training data and more processors to create better models. Simply put, it was more of the same. We can call this Phase One.
As people began using these services, we collectively discovered that a technique called chain-of-thought significantly improved AI performance. This involves prompts that include step-by-step instructions: "First do X, then Y, then Z." This method delivered astonishing results, such as financial analysis more accurate than that of human financial analysts.
OpenAI learned from this and integrated chain-of-thought into its models, now referring to all future models as reasoning models. The idea of AI reasoning with itself is nearly as old as AI itself, but it wasn’t until the strength of chain-of-thought became apparent that it was embedded into large language models. This has enabled the launch of new services, like Deep Research, which I wrote about recently.
Another key development came from DeepSeek. As a Chinese company, they lack access to the most advanced processors due to U.S. export restrictions. This forced them to be creative, leading them to develop a way to train an AI model without relying on a large number of high-performance processors. They also leveraged AI’s ability to reason with itself, which I explained in this article.
We have now entered Phase Two—where new ideas emerge on top of the old, as development always progresses. We discover things when using technology, encountering both opportunities and challenges.
This might seem like the most obvious observation ever, yet surprisingly many people fixate on current limitations, failing to see that these issues will either be solved or become less significant. Based on this, they draw far-reaching and incorrect conclusions.
The biggest challenge for large language models today is hallucinations. This is a problem that will be solved. We don’t yet know when or how, but it will happen one way or another.
Mathias Sundin
Angry Optimist
❗ Other stuff
📺 An excellent introduction to large language models like ChatGPT
Andrej Karpathy, who co-founded OpenAI and later led Tesla’s self-driving car development, provides a thorough yet accessible breakdown of how a large language model is built and how it functions.
😕 Ancient pessimism

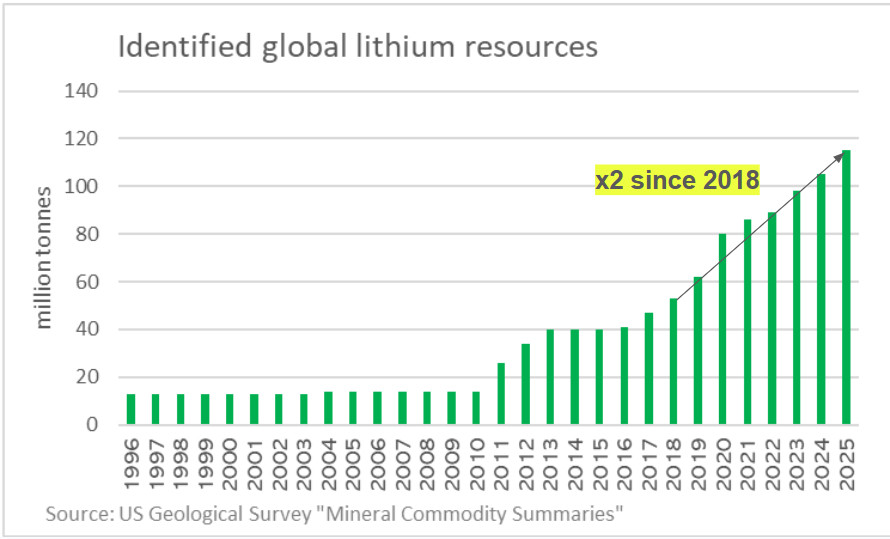
📈 "We’re going to run out of lithium!"
No.
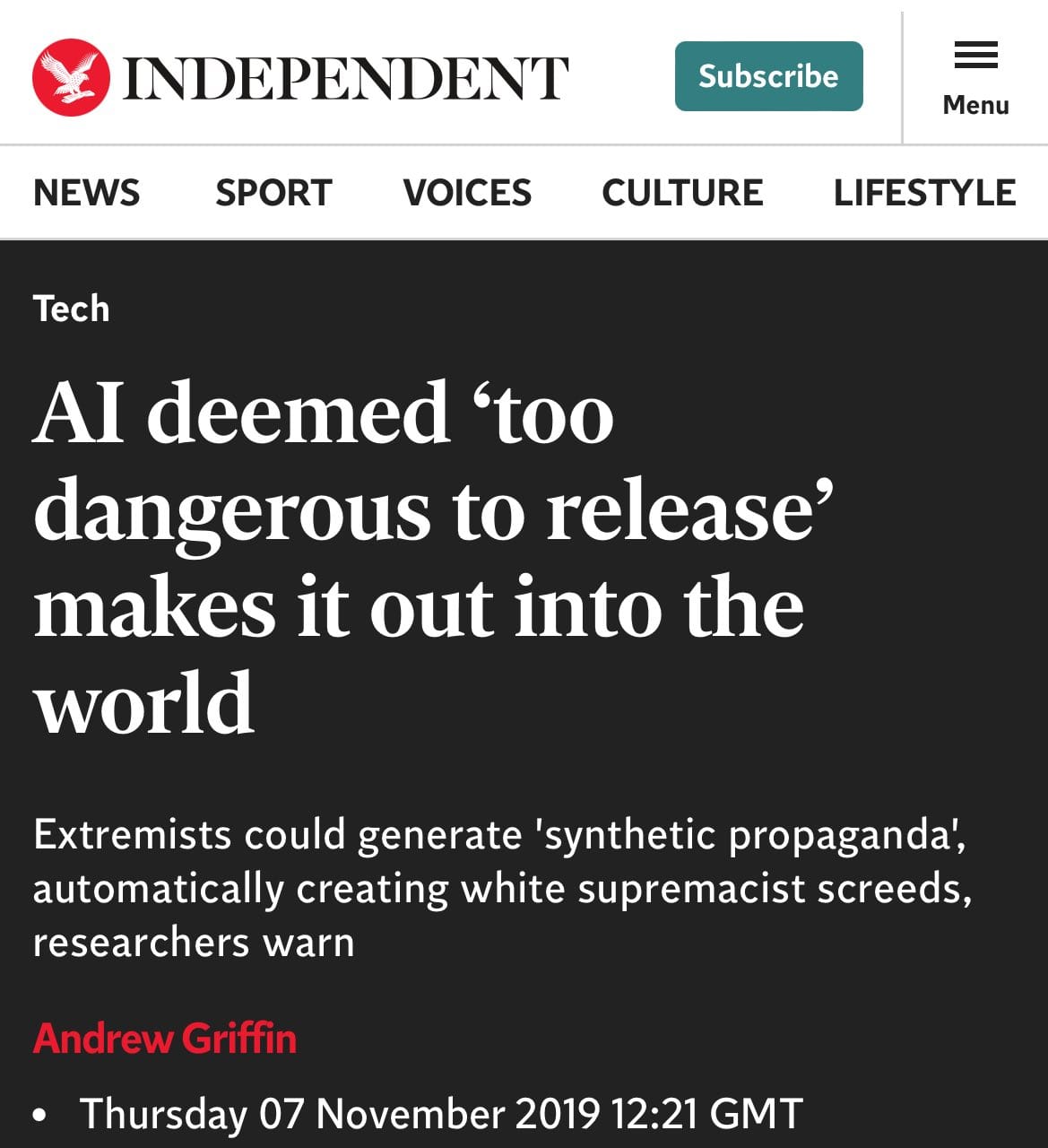
🤡 "Too dangerous to release!"
Remember, in 2019, people claimed GPT-2 was so powerful that it was too dangerous to be made publicly available.
Now we have GPT-4, with hundreds of millions of users, and those fears never materialized.
By becoming a premium supporter, you help in the creation and sharing of fact-based optimistic news all over the world.


